预加载TTS
从V2.3.0版本开始,新加入了一个预加载TTS的功能,该功能解决了之前串行调用TTS导致的两次TTS之间存在短暂的延迟问题。
问题
EasyMrcp调用TTS时可以进行多次调用,让一句话分多次生成。
例如:speak("你好呀,");
speak("我是EasyMrcp~");
如果第二个tts还没到执行的时间,将会把它加入队列中等待第一个完成后调用。
旧版中tts的执行是一个接着一个串行执行的,所以在两次的请求调用之间会存在着请求、首包响应的延迟。这在某些连续说话的场景中听起来就会有一些短暂的停顿,导致效果并不是很理想。 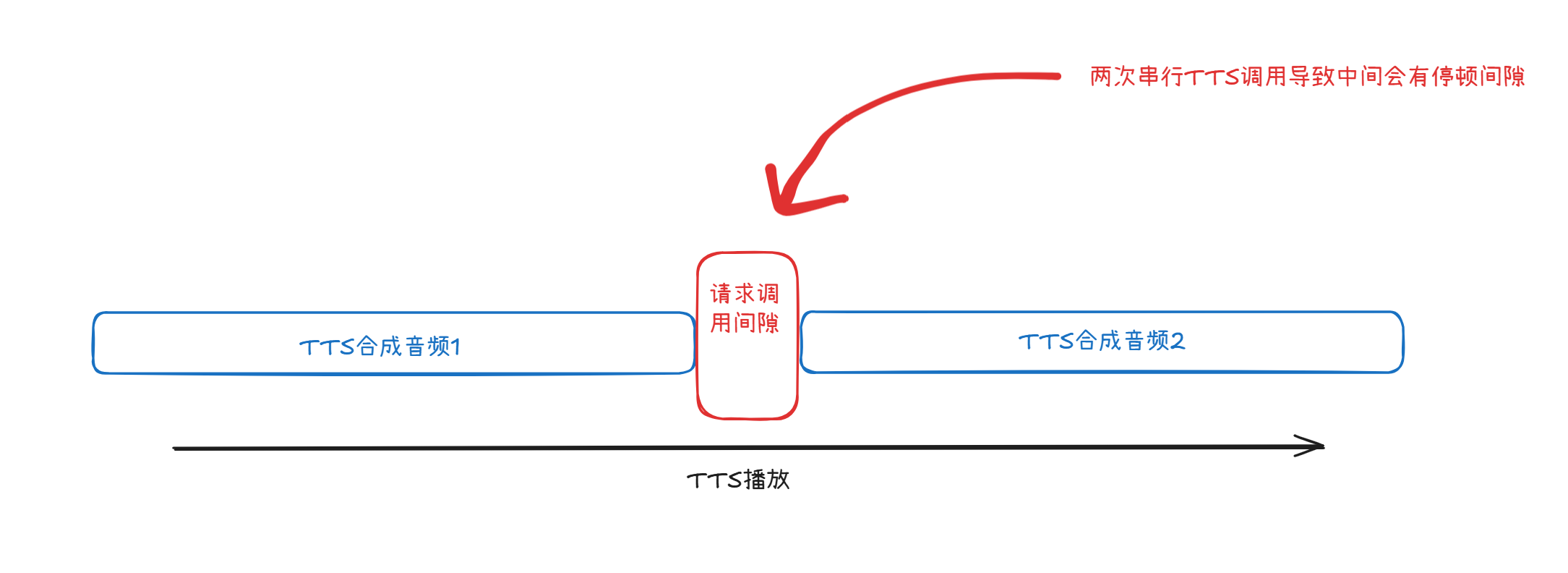
解决
针对上述问题加入了预加载TTS功能,也就是在执行TTS合成音频1的同时会检查时候还有TTS合成音频2,如果有则加载TTS合成音频2。Easymrcp会始终确保在播放或者加载当前音频时,如果有下一个音频加入了待播放的队列,那么就会自动加载下一个TTS。
TTS合成请求时序如下所示: 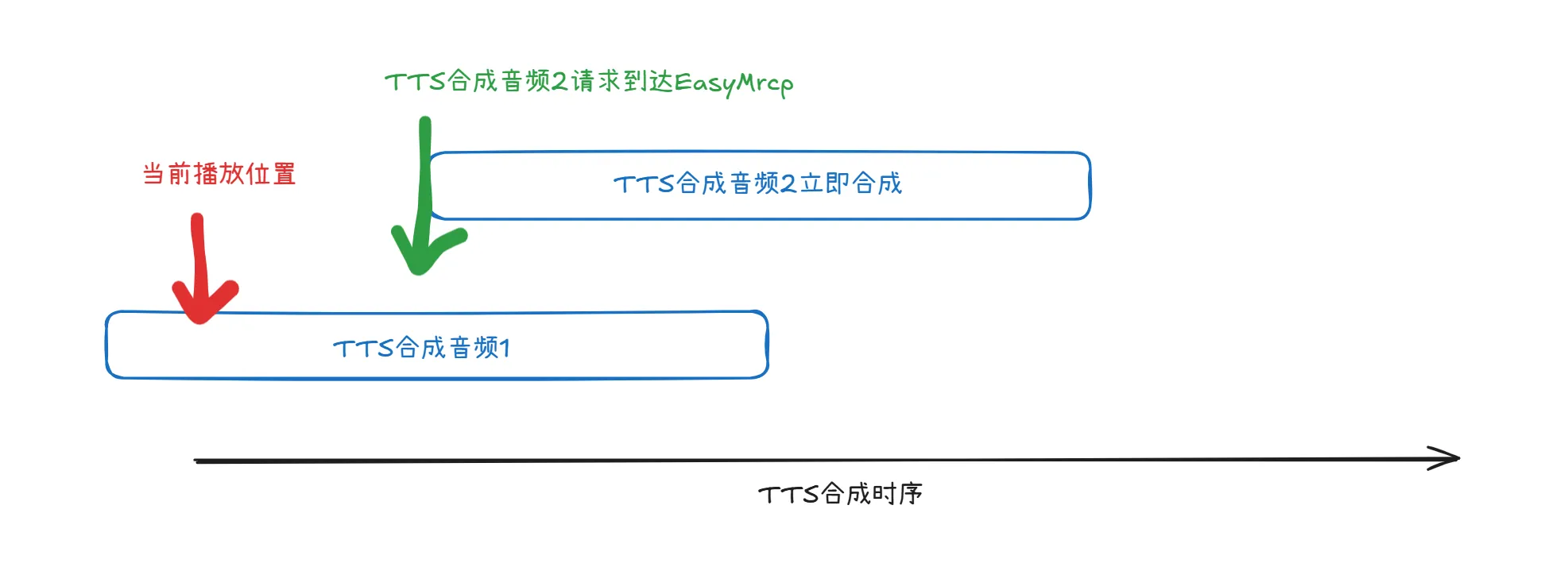
当TTS合成音频1播放完成后就会直接从缓存中播放TTS合成音频2,从而去除了请求间隙问题。 后面的TTS合成音频3、4、5.....等等音频也是同样的逻辑,播放上一个时就会加载下一个。 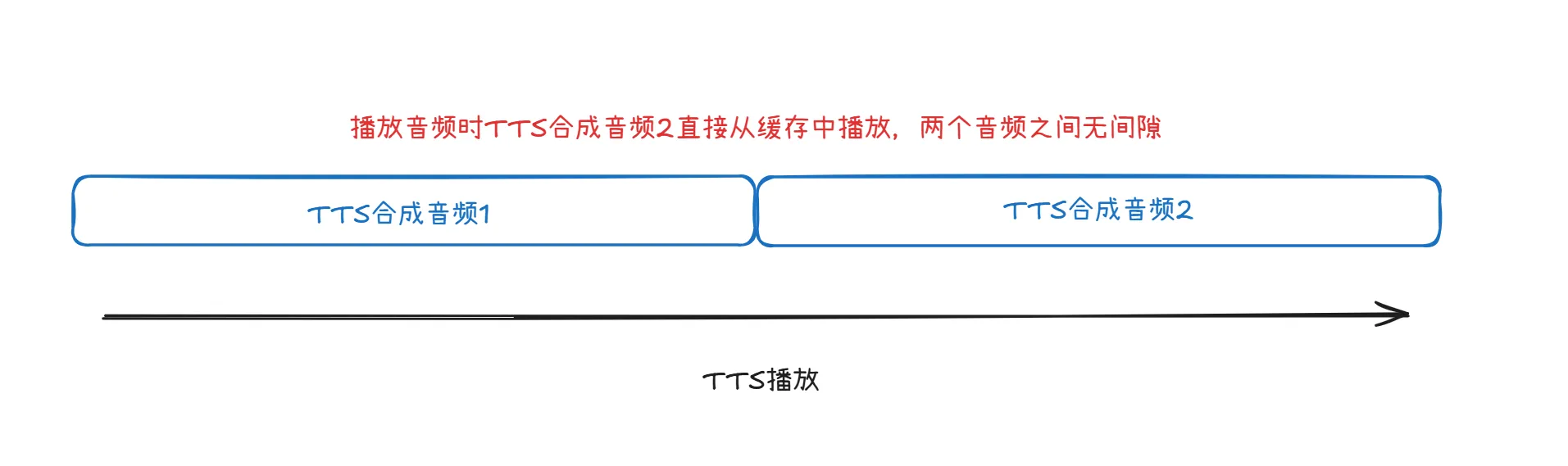
优化
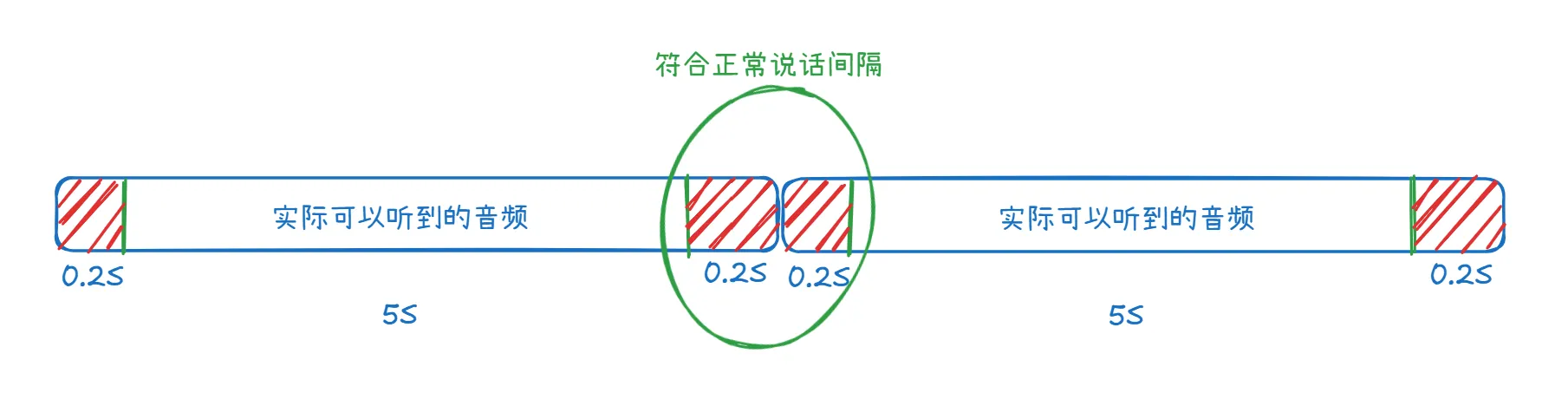
做完上述优化后真的天衣无缝了吗?在实际的测试中还发现了一个问题,就是TTS合成音频首尾本身就有一定的空白时间。
例如使用阿里的cosyvoice-v3-flash进行合成的时候,发现音频前后都有大约0.4秒的空白时间,这段时间之内是完全没有任何音频的。 
所以即使做到TTS音频拼接的0延迟,在实际的播放中仍然会有大约1s的延迟问题。这个1s的延迟导致离理想状态下将两个句子完美拼接还是有一些差距的。听起来还是可以感觉到延迟问题。 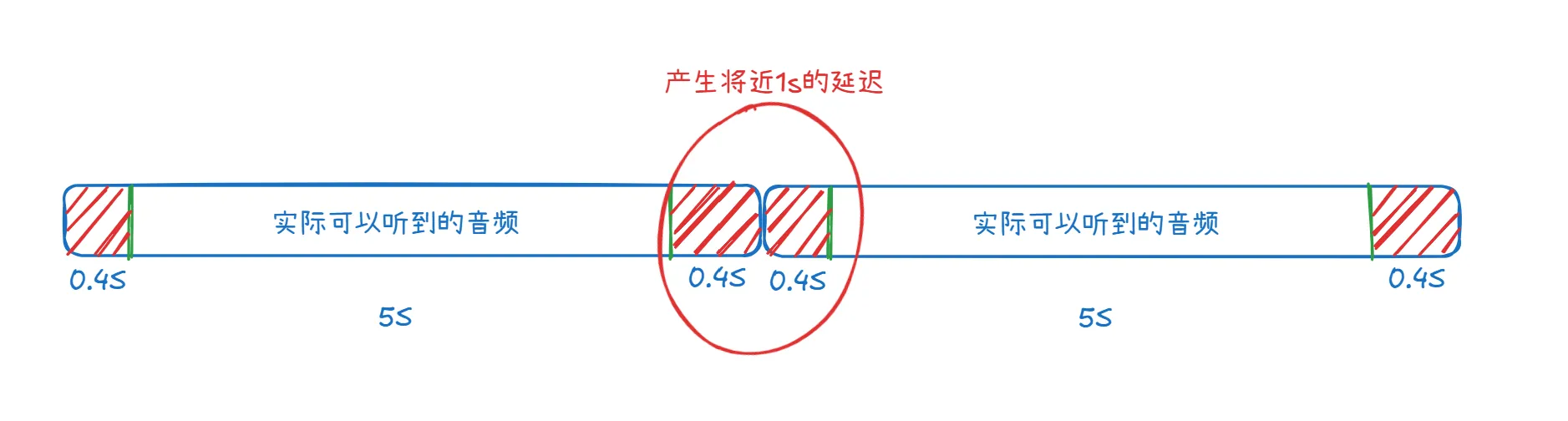
所以EasyMrcp在TTS配置中新加了两个参数skipBytesInTheFirstPacket、skipBytesInTheEndPacket。这两个参数用来跳过首尾多余的字节数。
skipBytesInTheFirstPacket(首包跳过字节数):
由于tts的语音开始有一小段时间的无音频,所以需要跳过的开头的字节(PCM格式)
例如使用:PCM 8kHz 16bit,那么跳过0.1秒音频就是:8000 * 2 * 0.1 = 1600字节
注意:该值是理论最大值,实际使用中可能由于首包小于设定字节数而变小。
skipBytesInTheEndPacket(尾包跳过字节数):
由于tts的语音结尾有一小段时间的无音频,所以需要跳过的末尾的字节(PCM格式)
例如使用:PCM 8kHz 16bit,那么跳过0.1秒音频就是:8000 * 2 * 0.1 = 1600字节
注意:该值是理论最大值,当前系统中的默认配置无法超过3000字节。并且实际使用中可能由于尾包小于设定字节数而变小。
所以优化到这时,成功将两次tts合成之间的间隙缩小到人类正常说话的间隙。可以说,真正做到了天衣无缝。